❗ 本文最后更新于 3489 天前,文中所描述的信息可能已发生改变,请谨慎使用。
今天遇到一个 IE7 下 JSON.parse 失败的问题。经过排查发现:服务端某个配置文件编码是 UTF-8 + BOM,输出的字符串最开始包含了 BOM 字符,不是合法的 JSON。
IE7 不支持原生 JSON,我们项目中使用的是 json2.js,但解析不了开头有 BOM 字符的 JSON 不是 json2 的错,其他浏览器正常是因为它们忽略了响应正文开头的 BOM。如果像下面这样写,每个浏览器都会抛异常:
<script>
var a = '{"a":1}';
try {
JSON.parse(a);
} catch(e) {
alert(e.message);
}
</script>
把这段代码贴进无敌强大的 CodeMirror,就能轻松发现这个不可见的 BOM 字符:
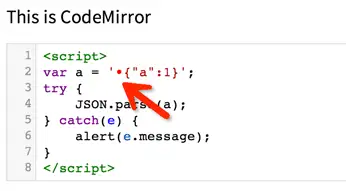
BOM 引发的问题多得数不胜数,网上相关记载也很多,这里不再啰嗦了。就今天遇到的情况来看,虽然问题出在接口提供方,但考虑到代码健壮性,也可以先 trim 字符串,再 JSON.parse。
String.prototype.trim 是 ES5 增加的方法,对于老旧浏览器,还得使用自己实现的 trim。我们先来看看 QWrap 和 jQuery 关于 trim 的实现:
//jQuery 1.7.2:
trimLeft = /^[\s\xA0]+/;
trimRight = /[\s\xA0]+$/;
return text == null ? "" : text.toString()
.replace( trimLeft, "" )
.replace( trimRight, "" );
jQuery 1.7.2 会过滤字符串两端的 \s 和 \xA0。对于IE 低版本,\s 等价于 [ \t\v\f\r\n]。这些字符的含义如下表:
| 名称 | Unicode 编码 | 字符串表示 | 说明 |
|---|---|---|---|
| <SP> | U+0020 | " ", "\x20", "\u0020" | 半角空格符,键盘空格键 |
| <TAB> | U+0009 | "\t", "\x09", "\u0009" | 制表符,键盘 tab 键 |
| <VT> | U+000B | "\v", "\x0B", "\u000B" | 垂直制表符 |
| <FF> | U+000C | "\f", "\x0C", "\u000C" | 换页符 |
| <CR> | U+000D | "\r", "\x0D", "\u000D" | 回车符 |
| <LF> | U+000A | "\n", "\x0A", "\u000A" | 换行符 |
| <NBSP> | U+00A0 | "\xA0", "\u00A0" | No-Break Space 禁止自动换行空格符 |
最后的「禁止自动换行空格符」<NBSP>,实际上就是 HTML 中经常用到的 。HTML 中,连续空白字符(半角空格、换行、tab 等)会被合并为一个空格, 则不会与其它相邻的空白字符合并。
可以看到,至少在 IE 低版本下,jQuery 1.7.2 无法过滤字符串两端的 BOM 字符。
//jQuery 1.8.1
rtrim = /^[\s\uFEFF\xA0]+|[\s\uFEFF\xA0]+$/g,
return text == null ?
"" :
text.toString().replace( rtrim, "" );
jQuery 1.8.1 在之前的基础上,又增加了 \uFEFF。它是 ES5 新增的空白符,叫「字节次序标记字符(Byte Order Mark)」,也就是前面提到的 BOM。
| 名称 | Unicode 编码 | 字符串表示 |
|---|---|---|
| <BOM> | U+FEFF | "\uFEFF" |
Unicode3.2 之前,\uFEFF 表示「零宽不换行空格(Zero Width No-Break Space)」;Unicode3.2 新增了 \u2060 用来表示零宽不换行空格,\uFEFF 就只用来表示字节次序标记了。
可以看到,jQuery 1.8.1 可以过滤 BOM。另外,考虑到某些浏览器实现的 trim 不过滤 <NBSP> 或 <BOM>,jQuery 加了一层检测,并不是存在原生 trim 就一定用原生的。
//QWrap 1.1.6
return s.replace(/^[\s\uFEFF\xa0\u3000]+|[\uFEFF\xa0\u3000\s]+$/g, "");
QWrap 的 trim,还增加了 \u3000。它是「表意文字空格(IDEOGRAPHIC SPACE)」,用于 CJK 统一表意文字,可以简单地认为它就是平时我们经常遇到的中文全角空格。
| Unicode 编码 | 字符串表示 | 说明 |
|---|---|---|
| U+3000 | " ", "\u3000" | IDEOGRAPHIC SPACE,CJK 全角空格 |
再来看看浏览器的 trim 应该处理哪些字符,ES5 文档中这样描述:
Let T be a String value that is a copy of S with both leading and trailing white space removed. The definition of white space is the union of WhiteSpace and LineTerminator.
也就是说字符串两端的 WhiteSpace 和 LineTerminator 都要去掉。
ES5 文档规定的 WhiteSpace,除了包含上面提过的 <SP>、<TAB>、<VT>、<FF>、<NBSP> 和 <BOM> 之外,还包含 <USP> 定义的其它空白字符,USP 表示 Unicode 中「Separator, Space」分类下的字符,具体内容如下(来源:1、2):
| Unicode 编码 | 说明 |
|---|---|
| U+0020 | SPACE,<SP> |
| U+00A0 | NO-BREAK SPACE,<NBSP> |
| U+1680 | OGHAM SPACE MARK,欧甘空格 |
| U+180E | Mongolian Vowel Separator,蒙古文元音分隔符 |
| U+2000 | EN QUAD |
| U+2001 | EM QUAD |
| U+2002 | EN SPACE,En 空格。与 en 同宽(em 的一半) |
| U+2003 | EM SPACE,Em 空格。与 em 同宽 |
| U+2004 | THREE-PER-EM SPACE,Em 三分之一空格 |
| U+2005 | FOUR-PER-EM SPACE,Em 四分之一空格 |
| U+2006 | SIX-PER-EM SPACE,Em 六分之一空格 |
| U+2007 | FIGURE SPACE,数字空格。与单一数字同宽 |
| U+2008 | PUNCTUATION SPACE,标点空格。与同字体窄标点同宽 |
| U+2009 | THIN SPACE,窄空格。em 六分之一或五分之一宽 |
| U+200A | HAIR SPACE,更窄空格。比窄空格更窄 |
| U+200B | Zero Width Space,<ZWSP>,零宽空格 |
| U+200C | Zero Width Non Joiner,<ZWNJ>,零宽不连字空格 |
| U+200D | Zero Width Joiner,<ZWJ>,零宽连字空格 |
| U+202F | NARROW NO-BREAK SPACE,窄式不换行空格 |
| U+205F | MEDIUM MATHEMATICAL SPACE,中数学空格。 用于数学方程式 |
| U+2060 | Word Joiner,同 U+200B,但该处不换行。 Unicode3.2 新增,代替 U+FEFF |
| U+3000 | IDEOGRAPHIC SPACE,表意文字空格。即全角空格 |
| U+FEFF | Byte Order Mark,<BOM>,字节次序标记字符。不换行功能于 Unicode3.2 起废止 |
再来看看文档对 LineTerminator 的定义,除了前面介绍过的 <LF>(Line Feed,换行符)和 <CR>(Carriage Return,回车符),还有两个:
| 名称 | Unicode 编码 | 说明 |
|---|---|---|
<LS> |
U+2028 | 行分隔符 |
<PS> |
U+2029 | 段落分隔符 |
可以看到,ES5 定义的 trim 方法十分强大。浏览器实现方面,我测试了 Chrome 和 Firefox,上述大部分不可见字符都能被过滤,也能被正则里的 \s 匹配到。
QWrap 或 jQuery 实现的 trim,则只处理了常见字符,通常也够用。如果需要与 ES5 更加一致的 trim,可以看看 es5-shim 这个项目:
var ws = "\x09\x0A\x0B\x0C\x0D\x20\xA0\u1680\u180E\u2000\u2001\u2002\u2003\u2004\u2005\u2006\u2007\u2008\u2009\u200A\u202F\u205F\u3000\u2028\u2029\uFEFF";
if (!String.prototype.trim || ws.trim()) {
// http://blog.stevenlevithan.com/archives/faster-trim-javascript
// http://perfectionkills.com/whitespace-deviations/
ws = "[" + ws + "]";
var trimBeginRegexp = new RegExp("^" + ws + ws + "*"),
trimEndRegexp = new RegExp(ws + ws + "*$");
String.prototype.trim = function trim() {
if (this === void 0 || this === null) {
throw new TypeError("can't convert "+this+" to object");
}
return String(this)
.replace(trimBeginRegexp, "")
.replace(trimEndRegexp, "");
};
}
本文链接:https://mailseason.com/post/bom-and-javascript-trim.html,参与评论 »
--EOF--
发表于 2013-12-07 11:23:13,并被添加「ES5、JavaScript、编码」标签,最后修改于 2015-05-04 09:14:59。查看本文 Markdown 版本 »
专题「JavaScript 漫谈」的其他文章 »
- 改进 ThinkJS 的异步编程方式 (May 15, 2015)
- AMD 的 CommonJS wrapping (Dec 05, 2013)
- FileSystem API 实现文件下载器 2 (Oct 01, 2013)
- 用 FileSystem API 实现文件下载器 (Oct 01, 2013)
- ES6 中的 Set、Map 和 WeakMap (Sep 23, 2013)
- ES6 中的生成器函数介绍 (Sep 20, 2013)
- 尝试 ES6 中的箭头函数 (Sep 11, 2013)
- 使用 Canvas 绘制背景图 (Aug 18, 2013)
- 异步编程:When.js快速上手 (Jun 23, 2013)
- JavaScript动画漫谈 (Nov 15, 2012)
Comments
Waline 评论加载中...