❗ 本文最后更新于 4069 天前,文中所描述的信息可能已发生改变,请谨慎使用。
各种基于 HTML5 的文件上传已经被大家玩得烂熟,常见的文件夹上传、拖拽上传以及拷贝剪切板数据上传,都可以在各大网盘、WebIM 中见到。本文实现的纯 JavaScript 多区块并发下载器,要使用到 FileSystem 中相对不那么常见的 FileWriter。
本文涉及知识较多,我并不打算全部介绍它们。示例代码中使用了 when.js 这个异步框架,它的用法请看官方文档或我写的《异步编程:WHEN.JS 快速上手》;文中涉及到的 HTTP 知识可以参考 RFC2616,或者《HTTP 权威指南》;本文代码仅在 Chrome 29+ 测试过,FileSystem 的完整浏览器支持度请直接去 CanIUse 查;本文未涉及到的 FileSystem 其它知识,请参考 html5rocks 的这篇文章,不过需要注意的这篇文章完成时间很早,部分代码已失效(如文中的 BlobBuilder 已被废弃);JavaScript 中的 Typed Array 也都可以在网上找到详细介绍。
再说一点,文中示例代码未做封装,也完全没有考虑异常流程。这是我写博客的一惯原则:示例代码只为了把事情讲明白,如果要在实际项目中使用,需要读者自己去思考并加工。
废话说完,正式开始今天的主题。。。
获取下载文件信息
我们的 HTTP 下载器目标是下载指定 URL 对应的文件。为了方便后面的处理,首先,我们要获取这个文件的基本信息。虽然实际应用中我们需要的信息往往会由服务端提供,但本文目标是「完全不借助服务端语言(如 PHP),只使用浏览器 JavaScript 将 Nginx 托管的文件下载到本地」,所以这里采用纯客户端方案。
我们关心的是文件大小(便于分配任务)和文件类型(保存时要用到)。这两个信息在 HTTP 响应头中都有,分别是 Content-Length 和 Content-Type,可以通过 XHR(XMLHttpRequest)拿到它们。XHR 的 readyState 有 0 - 4 几种状态,等于 2 的时候就可以拿到响应头了。
按照上面的分析,通过 XHR 给目标文件发送 GET 请求,并在 readyState 等于 2 时获取响应头信息,再 abort() 掉请求就可以了。但实际上,HTTP 协议规定了「HEAD」这种请求方法,更适合做这件事情。文档对 HEAD 是这样说明的:
HEAD 方法与 GET 方法的行为很类似,但服务器在响应中只返回首部,不会返回实体的主体部分。这就允许客户端在未获取实际资源的情况下,对资源的首部进行检查。服务器开发者必须确保返回的首部与 GET 请求所返回的首部完全相同。遵循 HTTP/1.1 规范,就必须实现 HEAD 方法。
少数服务器不支持 HEAD,本文直接忽略。现在开始编写我们的 URL 分析工具,代码如下:
function UriAnalyser(url) {
var deferred = when.defer();
var xhr = new XMLHttpRequest();
xhr.open('HEAD', url, true);
xhr.onreadystatechange = function() {
if(2 == this.readyState) {
var ret = {
mimeType : xhr.getResponseHeader('Content-Type'),
size : xhr.getResponseHeader('Content-Length') | 0
};
deferred.resolve(ret);
}
};
xhr.send();
return deferred.promise;
}
代码很简单,不用解释了。UriAnalyser 接收 URL 参数并返回 promise,在获取到相关信息后 resolve。试用下:
var url = 'http://dl.qgy18.com/file.zip';
when(UriAnalyser(url)).then(function(o){ console.log(o) });
> Object {mimeType: "application/zip", size: 7992987}
在 FileSystem 创建文件
接下来,我们要在浏览器的 FileSystem 中创建一个区域,用来保存即将下载到的文件。出于安全考虑,浏览器中的 FileSystem 运行在沙箱中。要使用它,首先需要请求权限:
window.requestFileSystem(type, size, successCallback, errorCallback);
type 是文件系统类型,有 window.TEMPORARY 和 window.PERSISTENT 两种常量,区别是:TEMPORARY 类型的数据随时可能会被浏览器删掉;PERSISTENT 数据不会被浏览器清理,但需要用户额外授权。size 是存储大小,以字节为单位。后两个参数分别是请求文件系统成功和失败对应的回调,successCallback 的第一个参数是对文件系统的引用,我们用 fs 表示,后面还会用到。
下面两个方法分别用来获取文件系统中的目录和文件(目标不存在则新建):
fs.root.getDirectory(dirName, {create: true}, function(dirEntry) { ... }, errorCallback);
fs.root.getFile(filePath, {create: true}, function(fileEntry) { ... }, errorCallback};
现在,我们编写「根据指定的文件名,在文件系统中创建对应空白文件」的方法如下:
function CreateFile(name) {
var deferred = when.defer();
window.webkitRequestFileSystem(window.TEMPORARY, 10 * 1024 * 1024, function(fs) {
var dir = (+ new Date).toString(36);
fs.root.getDirectory(dir, {create: true}, function(dirEntry) {
var file = dir + '/' + name;
fs.root.getFile(file, {create: true}, function(fileEntry) {
fileEntry.createWriter(function(fileWriter) {
var ret = {
fileEntry : fileEntry,
fileWriter : fileWriter
};
deferred.resolve(ret);
});
});
});
});
return deferred.promise;
};
这个 promise 会返回 fileEntry 和 fileWriter,后面会用到。试用下:
var file = 'a.js';
when(CreateFile(file)).then(function(o){ console.log(o) });
> Object {fileEntry: FileEntry, fileWriter: FileWriter}
开始下载
现在开始编写下载代码。要实现并发下载,首先要合理分配任务。HTTP 协议中规定可以使用请求头的 Range 字段指定请求资源的范围。例如服务端收到「Range : bytes=10-100」这样的请求头,只需要返回资源的 10-100 字节这部分就可以了,这样的响应状态码为 206。有些服务器不支持 Range,本文继续忽略。
现在,离最终目标越来越近了。我们只需要再实现支持指定 Range 的下载器和任务分配器就可以了。下载器比较简单,直接看代码:
function Downloader(url, mimeType, range) {
var deferred = when.defer();
var xhr = new XMLHttpRequest();
xhr.open('GET', url, true);
xhr.onreadystatechange = function() {
if (this.readyState == 4) {
if (this.response != null) {
var blob = new Blob(
[ new Uint8Array(this.response) ],
{ type: mimeType }
);
var ret = {
size : this.response.byteLength | 0,
blob : blob
};
deferred.resolve(ret);
}
}
};
xhr.setRequestHeader("Range", "bytes=" + range);
xhr.responseType = 'arraybuffer';
xhr.send();
return deferred.promise;
};
下载器继续使用 promise 实现,它会在获取到响应数据时 resolve,返回指定 Range 的数据和大小。这样,把所有下载器丢给 when.all(),就可以在所有任务完成后触发下一步操作,顺序还不会乱。
文件全部下载完后,通过 fileWriter.write 方法就可以写入前面获得的 fileEntry 了。需要注意的是,当前数据写完之后才能开始新的写入,否则会产生异常。是否写完可以通过 fileWriter.onwriteend 来获得。下载完一部分数据就写一部分当然也可以,原理是类似的。
我把下载器 XHR 的 responseType 设置为「arraybuffer」,是为了获取每个下载器得到的长度。把全部下载器得到的长度加起来,跟分析器得到的文件大小做对比,可以粗略地检查文件完整性。
任务分配和合并文件的代码不贴了,太占篇幅,请直接看最后 Demo 的源代码。
文件合并完成后,通过 fileEntry.toURL() 得到文件在 FileSystem 中地址,赋给 <a> 标签的 href,再 click() 下就可以自动下载到本地了。
解决跨域问题
浏览器对同一个域名的并发连接数有限制,为了更好的实现并发下载,最好使用不同的域名访问要下载的文件,这用域名泛解析很容易实现。但是这样又会导致 XHR 被同源策略所限制。
还好,我们有 CORS(Cross-Origin Resource Sharing),专门用来解决这个问题。在 Nginx 配置文件中加上这几行就可以了:
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods GET,POST,OPTIONS;
add_header Access-Control-Allow-Headers Range;
add_header Access-Control-Expose-Headers Content-Type,Content-Length;
重点看下后两行:Allow-Headers 用来设置允许 XHR 发送哪些请求头,必须加上前面提到的 Range;Expose-Headers 用来设置哪些响应头可以被 XHR 的 getResponseHeader 方法获得,必须加上分析器用到的 Content-Type 和 Content-Length。
Nginx 本身还有一个问题:对静态资源发起 OPTIONS 请求会得到「405 Not Allowed」,这个问题可以改成用 PHP 读取文件再输出来解决。但前面说过,本文讨论内容不依赖服务端语言。通过 Google 找到了一个方案,在 Nginx 配置中增加下面这一段就可以了:
location / {
if ($request_method = OPTIONS ) {
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods GET,POST,OPTIONS;
add_header Access-Control-Allow-Headers Range;
add_header Access-Control-Expose-Headers Content-Type,Content-Length;
return 200;
}
}
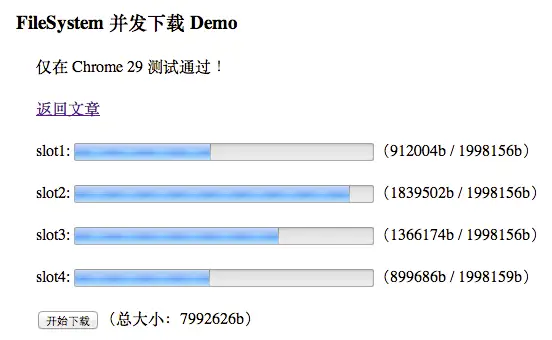
Demo
猛击这里观看 Demo,仅在 Chrome 29+ 测试通过。
本文链接:https://mailseason.com/post/a-downloader-with-filesystem-api.html,参与评论 »
--EOF--
发表于 2013-10-01 01:16:38,并被添加「FileSystem、HTML5」标签。查看本文 Markdown 版本 »
专题「JavaScript 漫谈」的其他文章 »
- 改进 ThinkJS 的异步编程方式 (May 15, 2015)
- BOM 和 JavaScript 中的 trim (Dec 07, 2013)
- AMD 的 CommonJS wrapping (Dec 05, 2013)
- FileSystem API 实现文件下载器 2 (Oct 01, 2013)
- ES6 中的 Set、Map 和 WeakMap (Sep 23, 2013)
- ES6 中的生成器函数介绍 (Sep 20, 2013)
- 尝试 ES6 中的箭头函数 (Sep 11, 2013)
- 使用 Canvas 绘制背景图 (Aug 18, 2013)
- 异步编程:When.js快速上手 (Jun 23, 2013)
- JavaScript动画漫谈 (Nov 15, 2012)
Comments
Waline 评论加载中...